In this article, we’ll provide a few tips and tricks on how to use a couple of simple advanced web searches to browse a website without actually visiting the target site, effectively remaining invisible to the site’s proprietors. Maybe the website is blocked on the computer you are using. Maybe the site seems somewhat sketchy and you want to check it out before you actually visit it. Maybe you want to read some content on the site while depriving them of your own web traffic. Maybe you don’t want the site’s proprietors to know your IP address. Whatever the case may be, if you have access to Google, you may very well be able to see the content you are looking for without ever connecting to the site in question.
Intro
For this article, we are going to use the website mediaite.com as our example target website. It has a good amount of content and is structured in a way that will make our demonstration fairly clear. If we just do a simple Google search for the name of the site, Mediaite, Google will return hits for the site itself, its Twitter page, a Wikipedia article, its Facebook page, references to it from other sites and so on.
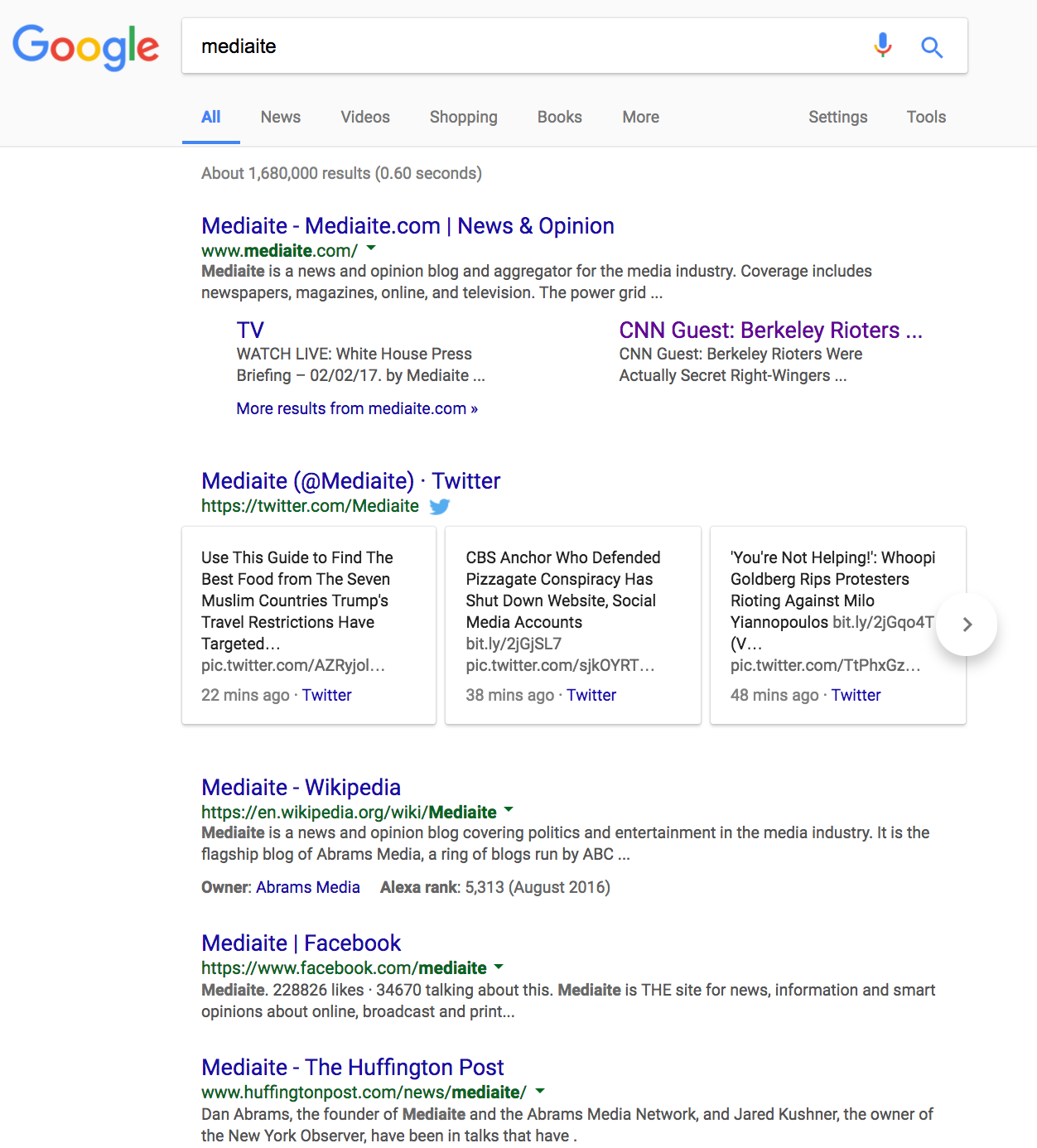
This is not very useful for seeing what sorts of content are on mediaite.com. We are thus going to use an advanced search operator so that Google only returns results that are from mediate.com itself.
Advanced Operator: Google Site Search
Google allows for the use of so-called “advanced search operators” in its search bar. With these operators, you can easily filter the results of your searches to only return specific types of content. One such advanced search operator, the site search operator, only returns results from a specific website. To run a search that will only return results from our target site, we use the operator term, then a colon, then the full address of the site. So, in the present case, we would enter the following into the Google search bar: site:mediate.com
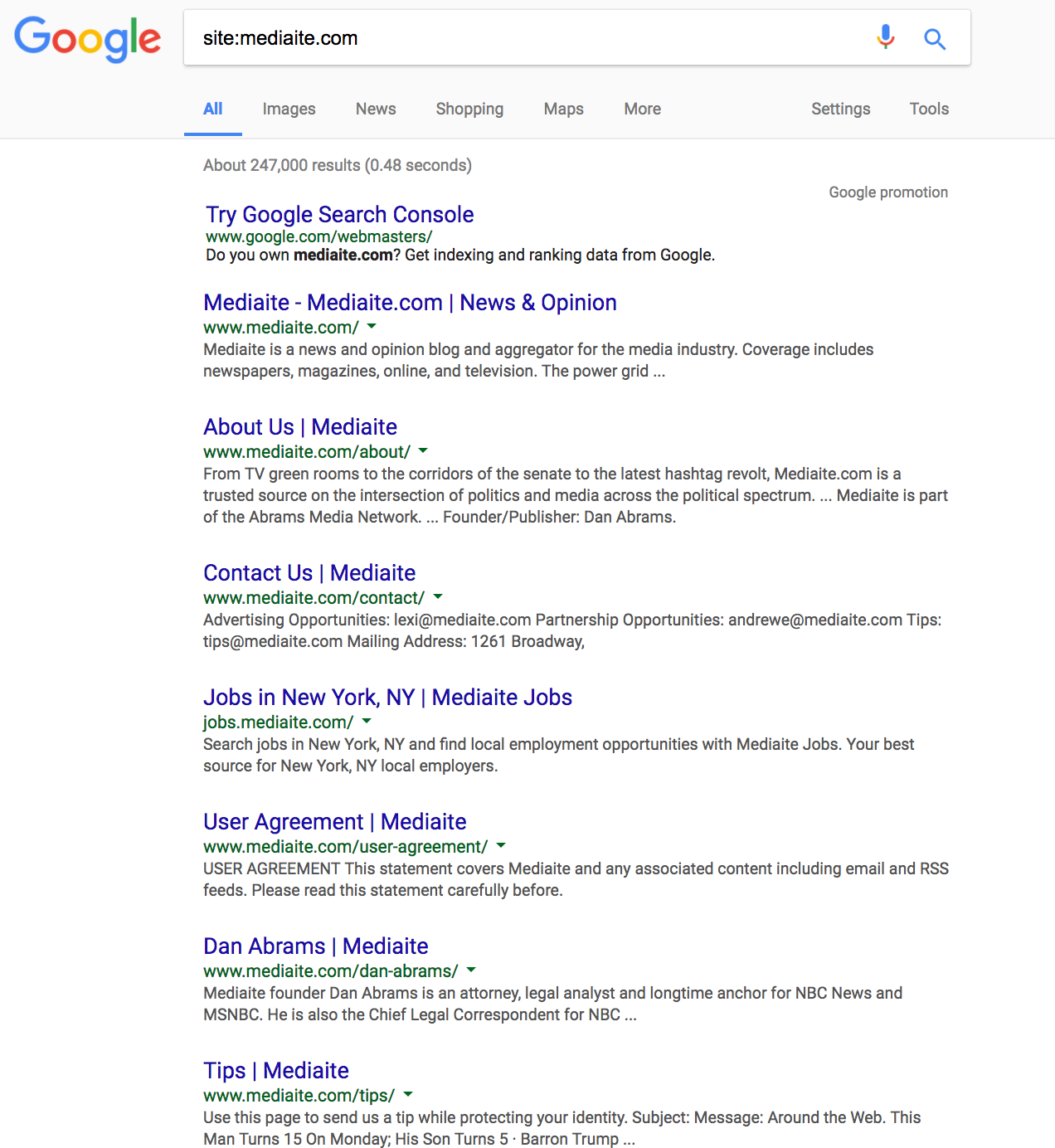
Now we are getting somewhere. You’ll notice that Google now only returns page results that are from our target site itself. We can get an overview of tons of content from our target site just from browsing through these results, to see what pages from the target Google has already indexed.
Browsing a Website’s Cached Pages
Okay, that’s all well and good, but we want to actually read content on the site itself, not just get an overview of its various pages! Notice, in the image above, or in any Google search results, that next to the web address of the page, there is a little downward pointing triangle. This is a dropdown menu. Click on the triangle and the dropdown menu will pop up, with two options: Cached and Similar.
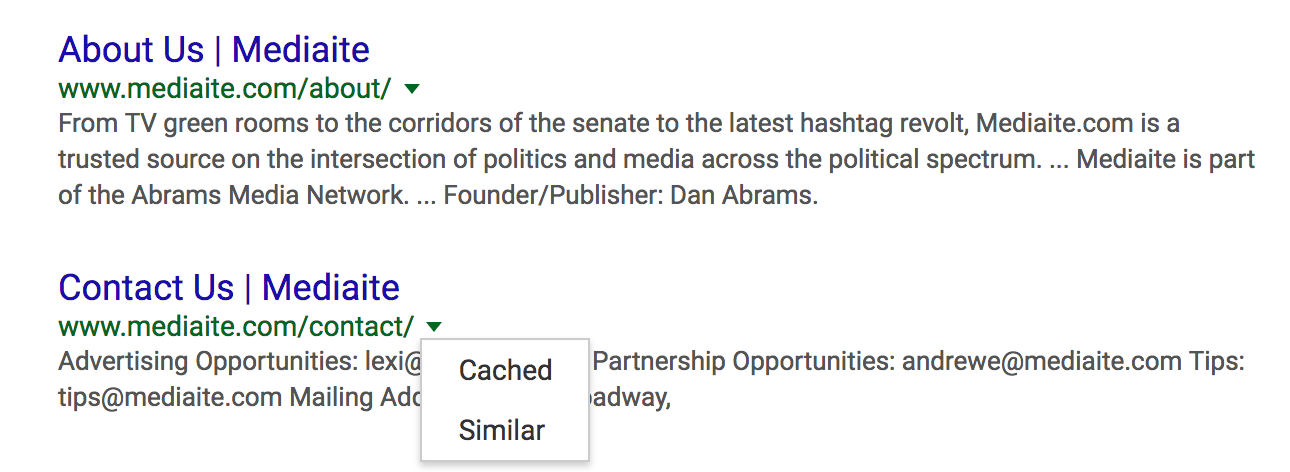
If you click on the “Cached” link, this will take you directly to the most recent snapshot of that page that Google has indexed. Here is a screengrab of Google’s cached version of Mediaite’s “Contact Us” page:

Notice the web address of this page: webcache.googleusercontent.com/search?q=cache . . . We are not viewing the page on the target server itself! We are viewing a snapshot of that page on one of Google’s servers. Now, Google’s Cached pages are NOT necessarily a snapshot of what that page looks like right now. But a widget at the top of the Cached page will tell you exactly when this snapshot was created.
Search a Site for Specific Cached Content
Now that we know how to search only for results from a specific site, and read that site’s content through Google’s cached pages, we can do a site search for specific terms and then read Google’s cached results for any of those pages. To do this, all we have to do is add our key term to the site search. Let’s say, we wanted to search for articles on the CIA at Mediaite. It’s pretty simple: site:mediaite.com CIA
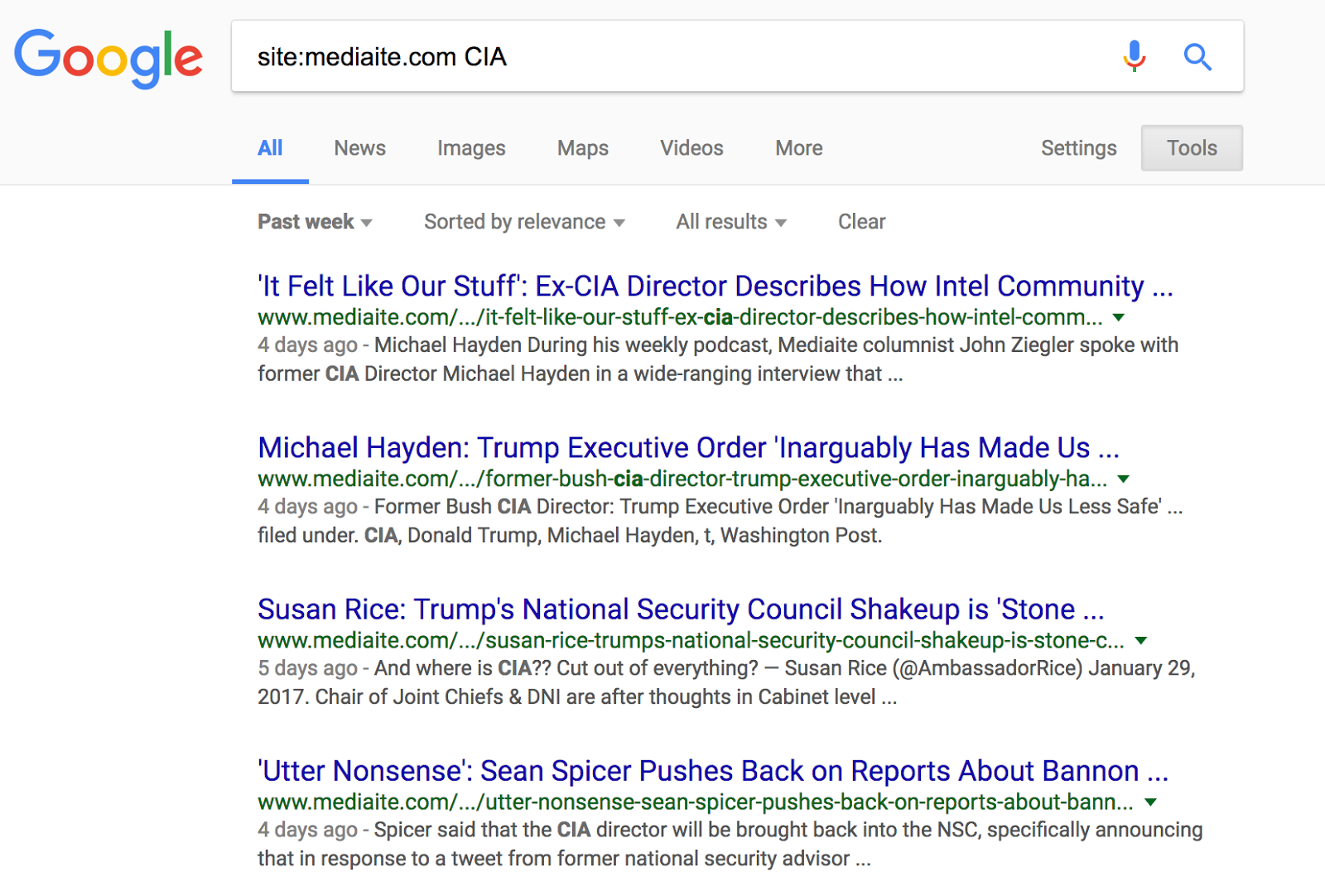
Once you’ve found the content you’re looking for in this way, all you have to do is click through to Google’s cached page, and you are reading the desired content from your target site without ever visiting it!
Conclusion and Caveats
With the help of Google’s site search and cached pages, we can easily locate and browse content on a target website without ever visiting that site. This means the proprietors of that site have no way of knowing what our IP address is, or when we read their content, or even that we ever read it at all. But we do have a couple of caveats here. Since we are using Google, Google’s servers still have a record of our IP address, what we searched for, when we accessed the cached page and so on. But the goal here was to hide this information from the target site, not from the search engine. Secondly, it is possible that the Cached page you are reading does not reflect the current content of the page. For example, if a website publishes a page, and then Google created a cached version of the page, but then the target website updates their page, the data in the Google cache will be stale and out of date, until the cache is updated again. That’s why it is important to look at the time stamp on the cached page, to get a sense of how old or out of date the content may be. And finally, it is possible that Google has not indexed or has no cached page of the specific content you are looking for. If that is the case, then you are out of luck trying to use this method of quasi-anonymous web browsing.
 !
!