GoSpider - Fast web spider written in Go
Painless integrate Gospider into your recon workflow?
this project was part of Osmedeus Engine. Check out how it was integrated at @OsmedeusEngine
Installation
GO111MODULE=on go install github.com/jaeles-project/gospider@latest
Features
- Fast web crawling
- Brute force and parse sitemap.xml
- Parse robots.txt
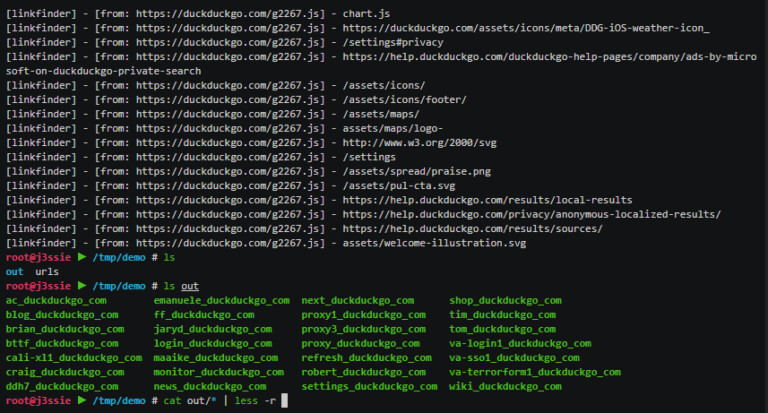
- Generate and verify link from JavaScript files
- Link Finder
- Find AWS-S3 from response source
- Find subdomains from response source
- Get URLs from Wayback Machine, Common Crawl, Virus Total, Alien Vault
- Format output easy to Grep
- Support Burp input
- Crawl multiple sites in parallel
- Random mobile/web User-Agent
Usage
Fast web spider written in Go - v1.1.5 by @thebl4ckturtle & @j3ssiejjj
Usage:
gospider [flags]
Flags:
-s, --site string Site to crawl
-S, --sites string Site list to crawl
-p, --proxy string Proxy (Ex: http://127.0.0.1:8080)
-o, --output string Output folder
-u, --user-agent string User Agent to use
web: random web user-agent
mobi: random mobile user-agent
or you can set your special user-agent (default "web")
--cookie string Cookie to use (testA=a; testB=b)
-H, --header stringArray Header to use (Use multiple flag to set multiple header)
--burp string Load headers and cookie from burp raw http request
--blacklist string Blacklist URL Regex
--whitelist string Whitelist URL Regex
--whitelist-domain string Whitelist Domain
-t, --threads int Number of threads (Run sites in parallel) (default 1)
-c, --concurrent int The number of the maximum allowed concurrent requests of the matching domains (default 5)
-d, --depth int MaxDepth limits the recursion depth of visited URLs. (Set it to 0 for infinite recursion) (default 1)
-k, --delay int Delay is the duration to wait before creating a new request to the matching domains (second)
-K, --random-delay int RandomDelay is the extra randomized duration to wait added to Delay before creating a new request (second)
-m, --timeout int Request timeout (second) (default 10)
-B, --base Disable all and only use HTML content
--js Enable linkfinder in javascript file (default true)
--subs Include subdomains
--sitemap Try to crawl sitemap.xml
--robots Try to crawl robots.txt (default true)
-a, --other-source Find URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com)
-w, --include-subs Include subdomains crawled from 3rd party. Default is main domain
-r, --include-other-source Also include other-source's urls (still crawl and request)
--debug Turn on debug mode
--json Enable JSON output
-v, --verbose Turn on verbose
-l, --length Turn on length
-L, --filter-length Turn on length filter
-R, --raw Turn on raw
-q, --quiet Suppress all the output and only show URL
--no-redirect Disable redirect
--version Check version
-h, --help help for gospider
Example commands
Quite output
gospider -q -s "https://google.com/"
Run with single site
gospider -s "https://google.com/" -o output -c 10 -d 1
Run with site list
gospider -S sites.txt -o output -c 10 -d 1
Run with 20 sites at the same time with 10 bot each site
gospider -S sites.txt -o output -c 10 -d 1 -t 20
Also get URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com)
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source
Also get URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com) and include subdomains
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source --include-subs
Use custom header/cookies
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source -H "Accept: */*" -H "Test: test" --cookie "testA=a; testB=b"
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source --burp burp_req.txt
P/s: gospider blacklisted .(jpg|jpeg|gif|css|tif|tiff|png|ttf|woff|woff2|ico) as default
gospider -s "https://google.com/" -o output -c 10 -d 1 --blacklist ".(woff|pdf)"
Show and Blacklist file length.
gospider -s "https://google.com/" -o output -c 10 -d 1 --length --filter-length "6871,24432"
License
Gospider is made with ![]() by @j3ssiejjj & @thebl4ckturtle and it is released under the MIT license.
by @j3ssiejjj & @thebl4ckturtle and it is released under the MIT license.